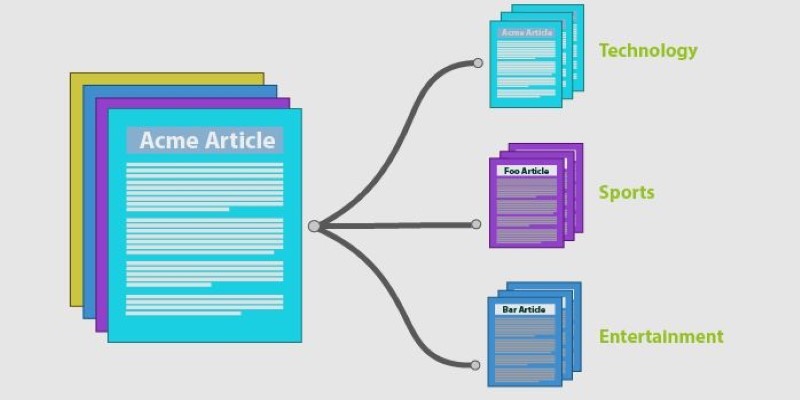
Every second, an immense amount of text is generated—emails, social media posts, financial statements, and customer feedback. Sorting through this endless stream manually isn't just impractical—it's impossible. That's where text classification steps in, enabling computers to read, understand, and categorize text just like humans but with greater speed and consistency.
From spam email detection to identifying fraudulent financial transactions and interpreting market patterns, text classification enables companies to make quicker data-driven decisions. But what drives this technology? And why is it so crucial in today's world of increasing speed? Let's break it down clearly and straightforwardly.
Understanding Text Classification
Text classification is the act of categorizing text into a set of defined categories. It enables machines to identify patterns in language, enabling them to process and categorize information effectively. Imagine teaching a computer how to read and categorize information like a human being—but much quicker and unbiased.
At its essence, this method depends on machine learning text processing in which algorithms learn from previous text data to accurately classify new material. For instance, banks employ text classification to review earnings statements, identify fraudulent activities, and determine customer mood. Automating these tasks results in faster, more accurate decisions with fewer human mistakes.
There are various methods for text classification. The most straightforward one is rule-based classification, in which predefined rules define text classification. Nonetheless, this method fails with very big and sophisticated data sets. Advanced methods utilize machine learning and natural language processing (NLP) to recognize linguistic patterns, thereby improving over time regarding accuracy in classifying text.
How Machine Learning Enhances Text Classification?
Machine learning has revolutionized text classification by allowing systems to learn with experience. Rather than relying on pre-programmed rules, these models analyze enormous amounts of data to discover patterns and interdependencies between words. This enables them to learn better about new and evolving sources of text.

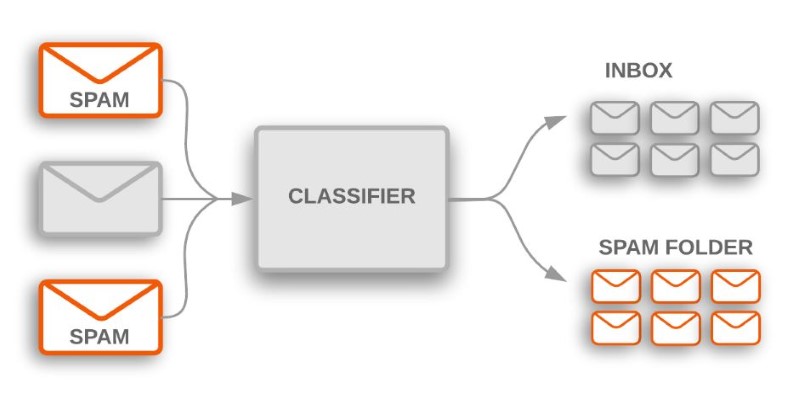
One of the popular techniques in machine learning text processing is supervised learning. In this, a model is trained using labeled examples—pre-classified text. The system learns from these examples and uses its knowledge to classify new, unseen text. One classic example is the detection of spam in emails. The system looks at thousands of messages marked as "spam" or "not spam" and learns to identify the features of spam emails.
Unsupervised learning, on the other hand, works without predefined categories. Instead, the system groups similar texts together based on patterns and structures it discovers in the data. This is useful when dealing with large volumes of unstructured text, such as financial reports or customer reviews, where predefined labels may not be available.
Another powerful approach is deep learning, which uses neural networks to process and classify text. These models can detect complex language patterns and even understand context, making them highly effective in applications like fraud detection, financial analysis, and automated trading strategies.
Applications of Text Classification in Finance
In the financial industry, text classification plays a critical role in analyzing and interpreting massive amounts of textual data. Financial institutions, investment firms, and regulatory bodies use this technology to enhance decision-making, improve customer service, and detect risks.
One major application is sentiment analysis, where text classification determines the mood or opinion behind financial news, earnings reports, or social media discussions. Investors use sentiment analysis to gauge market trends and make informed decisions based on public perception.
Another crucial use is fraud detection. Financial fraud often involves suspicious patterns hidden within text data, such as transaction descriptions, customer complaints, or support messages. By classifying text related to fraud, banks, and financial institutions can identify potential threats and prevent losses.
Text classification is also essential for regulatory compliance. Financial organizations must comply with strict regulations, which require constant monitoring of documents, reports, and communication records. Automated text classification ensures that regulatory guidelines are followed and helps detect potential violations.
Moreover, text classification is improving customer service automation in the financial sector. Banks and fintech companies use AI-powered chatbots that classify and respond to customer inquiries based on their content. This reduces response times and improves the overall customer experience.
Challenges and Limitations of Text Classification
While text classification offers significant advantages, it also faces several challenges that impact its accuracy and effectiveness. One major issue is data quality. Machine learning models rely on large datasets for training, but if these datasets are biased, incomplete, or outdated, the classification results can be inaccurate or misleading. This is particularly concerning in fields like finance, where misclassifications can lead to poor investment decisions or compliance issues.
Another major hurdle is language complexity. Human language is highly nuanced, with variations in slang, context, and even sarcasm. While deep learning has improved text understanding, machines still struggle to interpret tone, cultural differences, and subtle linguistic cues. This makes it difficult to achieve consistently accurate classifications, especially in dynamic industries where language evolves rapidly.
Constant updates and retraining are essential for text classification models to stay relevant. As language evolves, outdated models risk misclassifying text. Regular updates ensure accuracy, but they require ongoing data refinement, time, and expertise. Despite these challenges, advancements in machine learning and natural language processing continue to enhance the reliability and effectiveness of text classification systems.
Conclusion
Text classification is revolutionizing how businesses and financial institutions manage text data. With machine learning and natural language processing, companies can automate decision-making, detect fraud, and enhance customer interactions. From analyzing market sentiment to ensuring regulatory compliance, this technology streamlines operations and improves accuracy. Its ability to process vast amounts of information quickly makes it indispensable in today's data-driven world. As AI advances, text classification will continue to evolve, driving greater efficiency and innovation. Whether in finance, customer service, or cybersecurity, its impact is undeniable, making it a crucial tool for modern industries navigating an increasingly digital landscape.