In machine learning and AI, getting the best model performance is very important. Two problems that often happen with this performance are overfitting and underfitting. Overfitting happens when a model gets too complicated and fits the training data too well. Overfitting, on the other hand, happens when the model is too simple and can't find the patterns in the data. Finding the middle ground between these two extremes is important for making AI models that work well in general and make good guesses on new data.
What is Overfitting?
Overfitting happens when a model gets too complicated and starts to "memorize" the training data instead of learning how to use new data in a general way. It means that the model does a great job with data it has already seen but can't correctly guess new data it hasn't seen yet.
The Key Indicators of Overfitting:
- Highly accurate on the training set
- Not good on validation or test data
- A model that is too detailed, capturing noise instead of underlying trends
Overfitting is like trying to memorize answers to a specific set of questions rather than learning the broader concept. It often happens when a model has too many parameters or is trained for too long on limited data.
What is Underfitting?
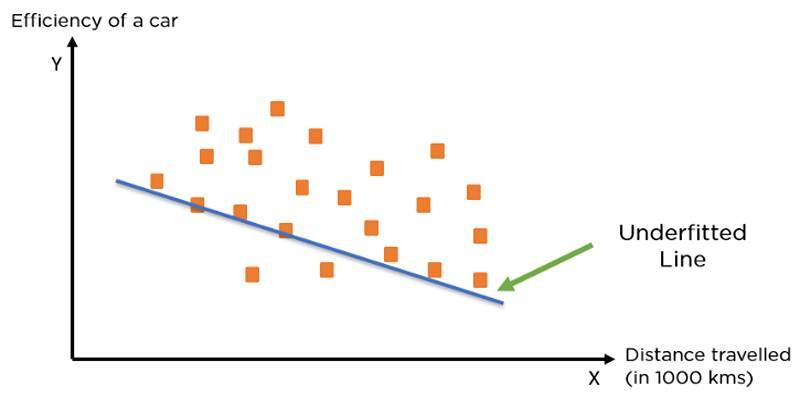
When a model is too easy to pick up on the patterns in the data, on the other hand, this is called underfitting. It makes the model do badly on both the training set and new data that it has never seen before. It's possible that the model isn't complicated enough to learn the underlying links, which would mean that the predictions are wrong.
The Key Indicators of Underfitting:
- Low accuracy on both training and test sets
- A model that is too simplistic, unable to grasp complex patterns
- The use of too few parameters or overly simplified models
Underfitting is like trying to answer questions without understanding the core material at all, which leaves the model unable to predict even the simplest outcomes accurately.
How Overfitting and Underfitting Affect AI Model Performance
Both overfitting and underfitting are harmful to machine learning models but in different ways. While overfitting leads to a model that is overly tailored to training data, underfitting results in a model that cannot learn enough from the data. Ideally, a model should be able to generalize well to unseen data, which means balancing complexity and simplicity. Without this balance, the model's predictions will be inaccurate and unreliable.
Impact of Overfitting on AI Model:
- Reduced model generalization
- Increased error rate on new, unseen data
Impact of Underfitting on AI Model:
- Poor model performance on all datasets
- Lack of complexity in predictions
Techniques to Prevent Overfitting
There are several strategies that data scientists use to avoid overfitting. These techniques aim to reduce the complexity of the model while still capturing the essential patterns in the data.
Regularization:
Regularization techniques like L1 and L2 penalties add a cost for larger model parameters, which encourages the model to keep things simpler and avoid fitting noise.
Cross-Validation:
Cross-validation is the practice of dividing the data into multiple parts and training the model on different subsets. It allows for a better assessment of the model's ability to generalize to new data.
Pruning:
In decision trees, pruning removes unnecessary branches that don't contribute much to the model's predictive power, effectively simplifying the model.
Techniques to Prevent Underfitting
While overfitting requires reducing complexity, underfitting calls for increasing the model’s ability to learn from the data. Here are a few techniques used to avoid underfitting:
Increase Model Complexity:
If a model is underfitting, it may be too simple to capture the relationships in the data. Adding more parameters or using a more complex algorithm can help the model learn better.
More Training Time:
Sometimes, a model requires more training to understand the underlying patterns. Allowing the model to train for longer can prevent it from underfitting, especially in deep-learning models.
The Role of Data in Overfitting and Underfitting
The quality and quantity of data play a significant role in both overfitting and underfitting. Too little data can cause a model to underfit, while an excess of data that isn't representative can lead to overfitting.
Data Quality:
High-quality data, with minimal noise and outliers, helps prevent overfitting by allowing the model to focus on the essential patterns. It also helps avoid underfitting by providing enough variability for the model to learn effectively.
Data Quantity:
A larger volume of data can prevent overfitting by allowing the model to better generalize across diverse scenarios. Conversely, too little data may lead to underfitting due to a lack of variation for the model to learn from.
Evaluating Model Performance: Balancing Overfitting and Underfitting

Once a model is trained, it is essential to evaluate its performance to check for overfitting or underfitting. It can be done using different metrics and techniques, including:
Accuracy:
Accuracy is the quantity of correctly predicted events. If the model is overfitting or underfitting, though, depending only on accuracy can be confusing, so other measures are often used.
Precision and Recall:
Precision shows how many of the positive statements came true, and recall shows how many of those positives the model actually found. These measures can be used to judge model success in more ways than just accuracy.
F1 Score:
The F1 score combines precision and recall into a single metric, offering a better overall assessment of the model’s predictive power.
Conclusion
Overfitting and underfitting are two of the most common challenges faced when building AI models. However, with the right techniques and a balanced approach, it's possible to create models that perform well across both training and unseen data. By carefully managing model complexity, ensuring sufficient data quality, and applying strategies like regularization and cross-validation, AI practitioners can build models that generalize effectively, providing reliable predictions.